In problem 198, a number,  , is defined to be ambiguous for the denominator
, is defined to be ambiguous for the denominator  if has two best approximations by rationals with denominators no bigger than . And then an is ambiguous if it is ambiguous for some denominator. The problem is to determine how many ambiguous rationals there are in a certain interval, with a certain bound on the denominator.
if has two best approximations by rationals with denominators no bigger than . And then an is ambiguous if it is ambiguous for some denominator. The problem is to determine how many ambiguous rationals there are in a certain interval, with a certain bound on the denominator.
Yes, I’m getting to this problem a little out of order. Jaime told me to. I was talking about Neighbors in Farey Sequences, on another blog, and he said this problem would fit well with what I was doing. In fact, if you don’t know about Farey sequences, you should probably go to that post (or Wikipedia) and read up, because I’m going to assume you know about them.
Once you have read a little about Farey sequences, you realize a number is ambiguous for a denominator if the number is the midpoint of neighbors in the appropriate Farey sequence. Moreover, the midpoint of Farey neighbors is always reduced, so you don’t have to worry about finding gcds. Also, Farey sequences can be easily generated inductively, by inserting the “mediant” between neighbors, when appropriate.
So a first go at this problem would be to use that idea. My first solutions are always ones that are completely stupid, but I’m pretty convinced are correct. So they’re slow, but good for testing optimizations or other solutions (for small inputs, anyway). Below is my third revision, approximately two orders of magnitude quicker than my first solution, an improvement gained by being slightly careful how far you iterate and what order you do things in. Oh, and I’m representing rationals as pairs of integers, to remain in the world of integer arithmetic. I worry about floating point operations when my denominators are allowed to be as big as 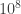 .
.
def midpoint(lhs, rhs):
""" Midpoint of lhs and rhs """
return (lhs[0]*rhs[1] + lhs[1]*rhs[0], 2*lhs[1]*rhs[1])
def solve(r, D):
""" Find ambiguous rationals
Find ambiguous p/q with:
1. p/q < 1/r (i.e. r*p < q)
2. q <= D
"""
seq = [(0,1), (1,1)] # F_1, the first Farey sequence
den = 1
ret = r < 2 and 1 or 0 # if 1/2 is included or not
while den < D:
# loop invariant: seq is the Farey sequence F_{den}
# at least up to 1/r
idx = 0 # our location in F_den
# iterate to the end of F_den or until seq[idx] > 1/r
while idx < len(seq)-1 and r*seq[idx][0] < seq[idx][1]:
nextidx = idx + 1
mediantden = seq[idx][1] + seq[idx+1][1]
if(mediantden == den + 1): # new element of F_{den+1}
mediant = (seq[idx][0]+seq[idx+1][0],mediantden)
seq.insert(idx + 1, mediant)
nextidx = idx + 2
# possible new ambiguous numbers
midleft = midpoint(seq[idx], mediant)
midright = midpoint(mediant,seq[idx+2])
if r*midleft[0] < midleft[1] and midleft[1] <= D:
ret += 1
if r*midright[0] < midright[1] and midright[1] <= D:
ret += 1
idx = nextidx
den += 1
return ret
This is still quite slow. I’m pretty sure it’d basically never solve the stated problem.
I spent some time thinking about ways to change the algorithm around and get the necessary speed improvements. I had spent some time thinking about neighbors in Farey sequences, and the extended Euclidean algorithm. I thought I could translate it into code that would iterate over reduced fractions, find neighbors for each, and count ambiguous numbers that way. It was a little messy, and then I realized I was over counting. And there seemed to be some boundary cases to worry about. I would still like to get a nice solution going along these lines.
But yesterday I came up with a recursive solution that runs quickly enough to solve the stated problem in about 10 minutes on my computer. That’s still 10 (or 100 :)) times longer than I usually shoot for on these problems, but I’ll take it (for now). It’s a pretty clean solution, I think. The idea is to loop through all the intervals ![[h/k, H/K]](https://s0.wp.com/latex.php?latex=%5Bh%2Fk%2C+H%2FK%5D&bg=ffffff&fg=333333&s=0&c=20201002) between neighbors in Farey sequences where (1) the interval contains points smaller than the specified bound, and (2) the product
between neighbors in Farey sequences where (1) the interval contains points smaller than the specified bound, and (2) the product  isn’t too big, for the specified denominator bound. Once you’ve got one such interval you can split the interval into two, at the mediant, and then run the same things on those two smaller intervals.
isn’t too big, for the specified denominator bound. Once you’ve got one such interval you can split the interval into two, at the mediant, and then run the same things on those two smaller intervals.
While the solution is essentially recursive, for whatever reason I ended coding it up as a loop. Here’s what I came up with:
def solve(r, D):
""" assumes D >= 2 """
# pairs will be my list of integrals to check
# an element is (h,k), (H,K), neighbors in a Farey sequence
# along with the denominator, 2*k*K, of the midpoint
pairs = [ [(0,1),(1,1), 2] ]
ret = 0
while len(pairs):
pair = pairs.pop()
midden = pair[2] # we already know this is <= D
midnum = pair[0][0]*pair[1][1] + pair[0][1]*pair[1][0]
if r * midnum < midden: # midpoint is small enough, ambiguous
ret += 1
# construct the mediant
mednum = pair[0][0] + pair[1][0]
medden = pair[0][1] + pair[1][1]
mediant = (mednum, medden)
# and the denominators of the next midpoints
leftden = 2 * pair[0][1] * medden
rightden = 2 * pair[1][1] * medden
# include each subinterval in the list of pairs
# as long as the midpoint denominator isn't too big
if leftden <= D:
pairs.append( [ pair[0], mediant, leftden ] )
if rightden <= D:
pairs.append( [ mediant, pair[1], rightden ] )
return ret
You can optimize this a bit. If you re-organize a little, don’t bother with tuples, and store some computed values, you can cut the running time nearly in half. That’s as much of an improvement as I’ve been able to make so far though. I look forward to doing better… but I do like the cleanliness of this solution. It’s 18 lines of code, and with some syntactic sugar (multiple assignments) could be reduced to or below 15, without harming readability much (perhaps depending on how readable you think it is now).
 digits is
digits is 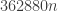 . An
. An  , so if
, so if 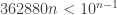 , then no number with
, then no number with 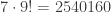 . We could clearly lower this bound some more, but let’s go with it for now.
. We could clearly lower this bound some more, but let’s go with it for now. where
where  , and we’ll also ignore
, and we’ll also ignore 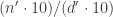 for digits
for digits  . Now take all these fractions that cancel like this, consider their product as a reduced fraction, and find the denominator. This is the challenge of
. Now take all these fractions that cancel like this, consider their product as a reduced fraction, and find the denominator. This is the challenge of 